Selected Publications

The Delta-Method and Influence Function in Medical Statistics: a Reproducible Tutorial.
Approximate statistical inference via determination of the asymptotic distribution of a statistic is routinely used for inference in applied medical statistics (e.g. to estimate the standard error of the marginal or conditional risk ratio). One method for variance estimation is the classical Delta-method but there is a knowledge gap as this method is not routinely included in training for applied medical statistics and its uses are not widely understood. Given that a smooth function of an asymptotically normal estimator is also asymptotically normally distributed, the Delta-method allows approximating the large-sample variance of a function of an estimator with known large-sample properties. In a more general setting, it is a technique for approximating the variance of a functional (i.e., an estimand) that takes a function as an input and applies another function to it (e.g. the expectation function). Specifically, we may approximate the variance of the function using the functional Delta-method based on the influence function (IF). The IF explores how a functional ϕ(θ) changes in response to small perturbations in the sample distribution of the estimator and allows computing the empirical standard error of the distribution of the functional. The ongoing development of new methods and techniques may pose a challenge for applied statisticians who are interested in mastering the application of these methods. In this tutorial, we review the use of the classical and functional Delta-method and their links to the IF from a practical perspective. We illustrate the methods using a cancer epidemiology example and we provide reproducible and commented code in R and Python using symbolic programming. The code can be accessed at https://github.com/migariane/DeltaMethodInfluenceFunction
In Arxiv 2022,
2022

Tutorial: computational causal inference for applied researchers
The purpose of many health studies is to estimate the effect of an exposure on an outcome. It is not always ethical to assign an exposure to individuals in randomised controlled trials, instead observational data and appropriate study design must be used. There are major challenges with observational studies, one of which is confounding that can lead to biased estimates of the causal effects. Controlling for confounding is commonly performed by simple adjustment for measured confounders; although, often this is not enough. Recent advances in the field of causal inference have dealt with confounding by building on classical standardisation methods. However, these recent advances have progressed quickly with a relative paucity of computational-oriented applied tutorials contributing to some confusion in the use of these methods among applied researchers. In this tutorial, we show the computational implementation of different causal inference estimators from a historical perspective where different estimators were developed to overcome the limitations of the previous one. Furthermore, we also briefly introduce the potential outcomes framework, illustrate the use of different methods using an illustration from the health care setting, and most importantly, we provide reproducible and commented code in Stata, R and Python for researchers to apply in their own observational study. The code can be accessed at https://github.com/migariane/TutorialCausalInferenceEstimators
In Arxiv 2020,
2020
Preprint
The `projects` parameter in `content/publication/CCI.md` references a project file, `content/project/cci.md`, which cannot be found. Please either set `projects = []` or fix the reference.

Using longitudinal targeted maximum likelihood estimation in complex settings with dynamic interventions
Longitudinal targeted maximum likelihood estimation (LTMLE) has very rarely been used to estimate dynamic treatment effects in the context of time-dependent confounding affected by prior treatment when faced with long follow-up times, multiple time-varying confounders, and complex associational relationships simultaneously. Reasons for this include the potential computational burden, technical challenges, restricted modeling options for long follow-up times, and limited practical guidance in the literature. However, LTMLE has desirable asymptotic properties, ie, it is doubly robust, and can yield valid inference when used in conjunction with machine learning. It also has the advantage of easy-to-calculate analytic standard errors in contrast to the g-formula, which requires bootstrapping. We use a topical and sophisticated question from HIV treatment research to show that LTMLE can be used successfully in complex realistic settings, and we compare results to competing estimators. Our example illustrates the following practical challenges common to many epidemiological studies: (1) long follow-up time (30 months); (2) gradually declining sample size; (3) limited support for some intervention rules of interest; (4) a high-dimensional set of potential adjustment variables, increasing both the need and the challenge of integrating appropriate machine learning methods; and (5) consideration of collider bias. Our analyses, as well as simulations, shed new light on the application of LTMLE in complex and realistic settings: We show that (1) LTMLE can yield stable and good estimates, even when confronted with small samples and limited modeling options; (2) machine learning utilized with a small set of simple learners (if more complex ones cannot be fitted) can outperform a single, complex model, which is tailored to incorporate prior clinical knowledge; and (3) performance can vary considerably depending on interventions and their support in the data, and therefore critical quality checks should accompany every LTMLE analysis. We provide guidance for the practical application of LTMLE.
In SIM,
2019
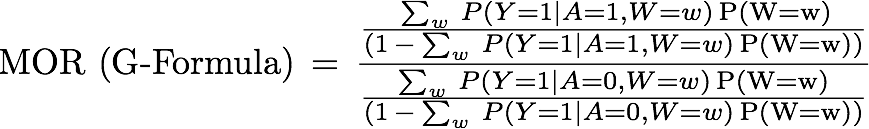
Effect Modification and Collapsibility in Evaluations of Public Health Interventions
The effect modification and collapsibility are critical concepts in epidemiological research when assessing the validity of using regression for the estimation of causal effects. Monte Carlo simulations and code supporting the letter can be found at Luque’s GitHub repository.
In AJPH 2019,
2019

Educational Note: Paradoxical collider effect in the analysis of non-communicable disease epidemiological data: a reproducible illustration and web application
Classical epidemiology has focused on the control of confounding, but it is only recently that epidemiologists have started to focus on the bias produced by colliders. A collider for a certain pair of variables (e.g. an outcome Y and an exposure A) is a third variable © that is caused by both. In a directed acyclic graph (DAG), a collider is the variable in the middle of an inverted fork (i.e. the variable C in A → C ← Y). Controlling for, or conditioning an analysis on a collider (i.e. through stratification or regression) can introduce a spurious association between its causes. This potentially explains many paradoxical findings in the medical literature, where established risk factors for a particular outcome appear protective. We use an example from non-communicable disease epidemiology to contextualize and explain the effect of conditioning on a collider. We generate a dataset with 1000 observations, and run Monte-Carlo simulations to estimate the effect of 24-h dietary sodium intake on systolic blood pressure, controlling for age, which acts as a confounder, and 24-h urinary protein excretion, which acts as a collider. We illustrate how adding a collider to a regression model introduces bias. Thus, to prevent paradoxical associations, epidemiologists estimating causal effects should be wary of conditioning on colliders. We provide R code in easy-to-read boxes throughout the manuscript, and a GitHub repository https://github.com/migariane/ColliderApp for the reader to reproduce our example. We also provide an educational web application allowing real-time interaction to visualize the paradoxical effect of conditioning on a collider http://watzilei.com/shiny/collider/
In IJE 2019,
2018

Targeted Maximum Likelihood Estimation: A tutorial
When estimating the average treatment effect for a binary outcome, methods that incorporate propensity scores, the G-formula, or Targeted Maximum Likelihood Estimation (TMLE) are preferred over naïve regression approaches which often lead misspecified models. Some methods require correct specification of the outcome model, whereas other methods require correct specification of the exposure model. Doubly-robust methods only require correct specification of one of these models. TMLE is a semi-parametric doubly-robust method that enhances correct model specification by allowing flexible estimation using non-parametric machine-learning methods and requires weaker assumptions than its competitors. We provide a step-by-step guided implementation of TMLE and illustrate it in a realistic scenario based on cancer epidemiology where assumptions about correct model specification and positivity (i.e., when a study participant had zero probability of receiving the treatment) are nearly violated. This article provides a concise and reproducible educational introduction to TMLE for a binary outcome and exposure. The reader should gain sufficient understanding of TMLE from this introductory tutorial to be able to apply the method in practice. Extensive R-code is provided in easy-to-read boxes throughout the article for replicability. Stata users will find a testing implementation of TMLE and additional material in the appendix and at the following GitHub repository: https://github.com/migariane/SIM-TMLE-tutorial
In SIM,
2018

Data-Adaptive Estimation for Double-Robust Methods in Population-Based Cancer Epidemiology: Risk differences for lung cancer mortality by emergency presentation
We propose a structural framework for population-based cancer epidemiology and evaluate the performance of double-robust estimators for a binary exposure in cancer mortality. We performed numerical analyses to study the bias and efficiency of these estimators. Furthermore, we compared two different model selection strategies based on 1) the Akaike and Bayesian Information Criteria and 2) machine-learning algorithms, and illustrated double-robust estimators’ performance in a real setting. In simulations with correctly specified models and near-positivity violations, all but the naïve estimators presented relatively good performance. However, the augmented inverse-probability treatment weighting estimator showed the largest relative bias. Under dual model misspecification and near-positivity violations, all double-robust estimators were biased. Nevertheless, the targeted maximum likelihood estimator showed the best bias-variance trade-off, more precise estimates, and appropriate 95% confidence interval coverage, supporting the use of the data-adaptive model selection strategies based on machine-learning algorithms. We applied these methods to estimate adjusted one-year mortality risk differences in 183,426 lung cancer patients diagnosed after admittance to an emergency department versus non-emergency cancer diagnosis in England, 2006–2013. The adjusted mortality risk (for patients diagnosed with lung cancer after admittance to an emergency department) was 16% higher in men and 18% higher in women, suggesting the importance of interventions targeting early detection of lung cancer signs and symptoms.
In AJE,
2017

Deconstructing the smoking-preeclampsia paradox through a counterfactual framework
Although smoking during pregnancy may lead to many adverse outcomes, numerous studies have reported a paradoxical inverse association between maternal cigarette smoking during pregnancy and preeclampsia. Using a counterfactual framework we aimed to explore the structure of this paradox as being a consequence of selection bias. Using a case–control study nested in the Icelandic Birth Registry (1309 women), we show how this selection bias can be explored and corrected for. Cases were defined as any case of pregnancy induced hypertension or preeclampsia occurring after 20 weeks’ gestation and controls as normotensive mothers who gave birth in the same year. First, we used directed acyclic graphs to illustrate the common bias structure. Second, we used classical logistic regression and mediation analytic methods for dichotomous outcomes to explore the structure of the bias. Lastly, we performed both deterministic and probabilistic sensitivity analysis to estimate the amount of bias due to an uncontrolled confounder and corrected for it. The biased effect of smoking was estimated to reduce the odds of preeclampsia by 28 % (OR 0.72, 95 %CI 0.52, 0.99) and after stratification by gestational age at delivery (<37 vs. ≥37 gestation weeks) by 75 % (OR 0.25, 95 %CI 0.10, 0.68). In a mediation analysis, the natural indirect effect showed and OR > 1, revealing the structure of the paradox. The bias-adjusted estimation of the smoking effect on preeclampsia showed an OR of 1.22 (95 %CI 0.41, 6.53). The smoking-preeclampsia paradox appears to be an example of (1) selection bias most likely caused by studying cases prevalent at birth rather than all incident cases from conception in a pregnancy cohort, (2) omitting important confounders associated with both smoking and preeclampsia (preventing the outcome to develop) and (3) controlling for a collider (gestation weeks at delivery). Future studies need to consider these aspects when studying and interpreting the association between smoking and pregnancy outcomes.
In EJEP,
2016

