The American Journal of Public Health series “Evaluating Public Health Interventions” offers excellent practical guidance to researchers in public health. In the 8th part of the series, a valuable introduction to effect estimation of time-invariant public health interventions was given.[1] The authors of this article suggested that in terms of bias and efficiency there is no advantage of using modern causal inference methods over classical multivariable regression modeling.[1] However, this statement is not always true. Most importantly, both “effect modification” and “collapsibility” are important concepts when assessing the validity of using regression for causal effect estimation.
Cancer epidemiology example
To discuss these concepts, we are looking at an example from cancer epidemiology. In this example, we are interested in the effect of dual treatment therapy (radio- and chemotherapy), compared to single therapy (chemotherapy only) on the probability of one-year survival among colorectal cancer patients. We know that there are confounders which affect both treatment assignment and the outcome, namely clinical stage, socioeconomic status, comorbidities, and age. Evidence shows that older patients with comorbidities have a lower probability of being offered more aggressive treatments and therefore they usually get less effective curative options. Also, colorectal cancer patients from lower socioeconomic status have a higher probability of presenting an advanced clinical stage at diagnosis, thus they usually get offered only palliative treatments.
Our structural assumptions in the cancer epidemiology example
The assumptions from above can be encoded in a directed acyclic graph (DAG) (Figure 1). Here, each circle represents a variable and an arrow from A to B (A -> B) means that we assume that A causes B. The combination of these structural assumptions and appropriate statistical methods allow us to estimate the causal effect of dual therapy versus monotherapy on colorectal cancer patients’ survival.
Figure 1 Directed Acyclic Graph

The question we want to answer
A clinician may be interested in the following:
how different would the risk of death have been had everyone received dual therapy compared to if everyone had experienced monotherapy? The causal marginal odds ratio (MOR) answers this question. Statisticians call this a “target quantity”. Each individual has a pair of potential outcomes: the outcome they would have received had they been exposed to dual treatment (A=1), denoted Y(1), and the outcome had they been unexposed, Y(0). The MOR is defined as:
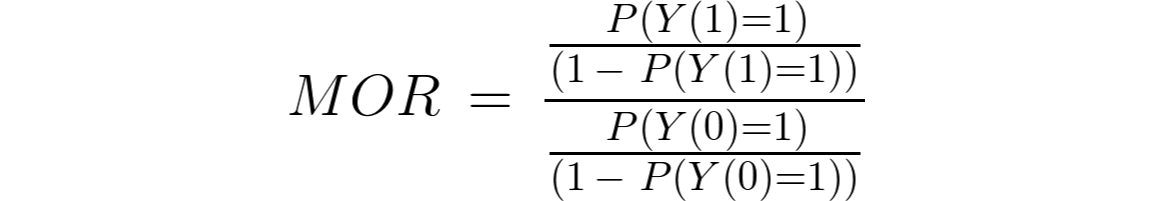
A common approach would be to use logistic regression to model the odds of mortality given the intervention, and adjust for the confounders (W) which are age (w1) socioeconomic status (w2), clinical stage (w3) and comorbidities (w4). Note that using a logistic regression, it estimates the conditional odds ratio (COR), which is:
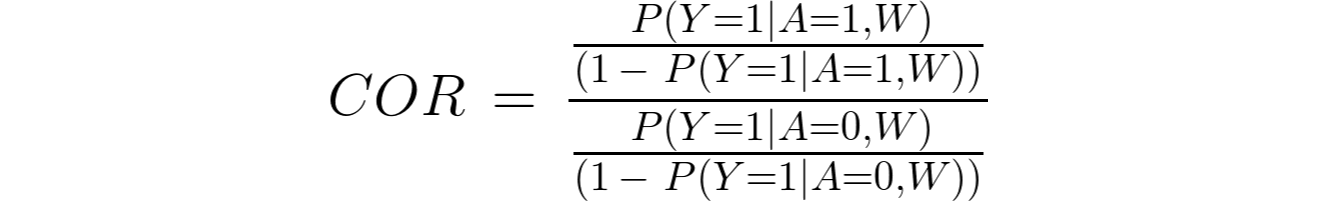
MOR and COR are typically not identical. First, if there is effect modification, e.g. if the effect of dual therapy is different for patients with no comorbidities compared to those having hypertension, then logistic regression (possibly including an interaction of treatment with one of the confounders) will not provide a marginal effect estimate, but only one conditional on the respective morbidity. To be more precise: we obtain an odds ratio that is valid for a given group of people, say those with hypertension, but it will not give us a marginal estimate. However, we are interested in a marginal estimate because we want to know if the dual therapy works in general. Of course, one may be specifically interested in patients with hypertension, but then the OR for this group is again conditional on the other variables, for example for elderly people, from a low socio-economic level, and advanced stage.
Second, the odds ratio is non-collapsible which means that the MOR is not necessarily equal to the stratum-specific OR, i.e. the COR. This statement holds even when W is only related to the outcome, and not the intervention, and is thus not a confounder.[2,3] In fact, it is even possible that the conditional odds ratio shows a benefit of the intervention in every stratum, but no benefit overall, i.e. marginally. This case is known as Simpson’s paradox. We encourage the reader to read the below references 2 and 3 plus Judea Pearls’ new book, The Book of Why for more insights. Please note that while the odds ratio is non-collapsible, other measures of association like the risk-difference and the risk ratios are collapsible.
Multivariable regression versus the G-Formula
To identify the MOR, classical epidemiologic methods, such as standard multivariable logistic regression models, where the treatment is included as a covariate in the analysis, require the assumption that the effect measure of the treatment of interest is constant across the levels of confounders included in the model.[4] However, in observational studies evaluating the effect of public health interventions, this is often not the case (i.e. the effect of the intervention might differ across individuals with different susceptibilities or characteristics). This is essentially the first point we made in the paragraph above. The second point says that certain effect measures, like the odds ratio, suffer from non-collapsibility.
Thus, in summary, as pointed out by Spiegelman et al [1] it can a be an option to use regression models to adjust for confounding; but we need to assume no effect modification and we need to choose a measure that is collapsible, like the risk difference, rather than the odds ratio.
An alternative to using multivariable regression adjustment is the G-Formula 5. In 1986, a seminal paper [5] demonstrated that under assumptions (conditional exchangeability, positivity, consistency, and non-interference, see Appendix below), a consistent estimate of the MOR can be obtained using the G-formula. G-computation,[6] based on the estimation of the components in the G-formula, allows for a treatment effect that may vary across the levels of the confounders. Furthermore, under the assumption that the DAG above (Figure 1) is correct and the other assumptions, we can estimate the MOR using the g-formula as follows:
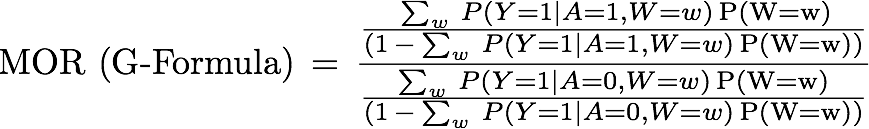
where P(W=w) refers to the marginal probability of w.
A Monte-Carlo simulation
We implement a Monte Carlo simulation based on the above population-based cancer epidemiology scenario and provide the R code for replication in this GitHub repository: (R script for simulation). As noted above, we are interested in how different the risk of death would have been had everyone received dual therapy compared to if everyone had experienced monotherapy. This is a relevant research question that, answered at a population level, may have an important public health implications for cancer patients.
Data generating process
We used the R-package simcausal [7] to generate data according to the DAG introduced above. The data are (W= (W1, W2, W3, W4), A, Y) where w1 refers to age, W2 to socioeconomic status, W3 to comorbidities, and W4 to cancer stage. The detailed setup can be found here (R script for simulation). In the outcome model, we included an interaction term between treatment A and both comorbidities (W2) and cancer stage (W4), based on the plausible biological mechanism that there is an increased risk of comorbidities among older adults and a different treatment effect for those patients with and without comorbidities and advanced cancer stage. The simulation is based on a sample size of 5000, and 10.000 simulation runs. We estimate the bias with respect to the MOR. Figure 2 shows the results of the above described Monte Carlo simulation.
Figure 2 Absolute bias with respect the marginal causal odds ratio comparing the conditional odds ratio from classical multivariable logistic regression models versus the marginal odds ratio from G-computation based on the G-Formula, n = 5,000 and 10,000 simulation runs.
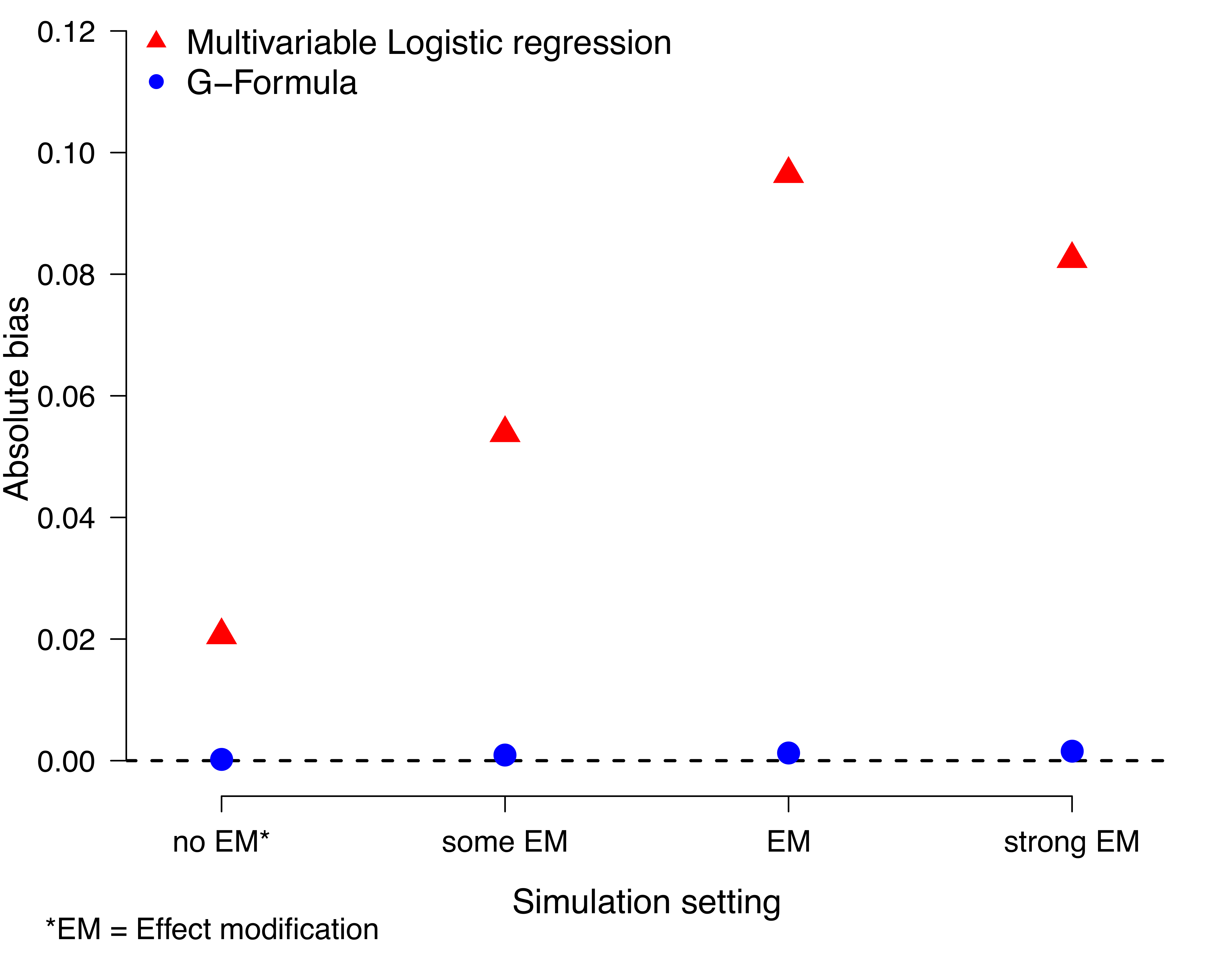
Briefly, one can see the bias of the multivariable logistic regression model is more pronounced under effect modification but persists -due to non-collapsibility- even under no effect modification.
Acknowledgements
MALF is supported by the Spanish National Institute of Health Carlos III Miguel Servet I Investigator Award (CP17/00206)
Figure legends
Figure 1. Directed Acyclic Graph.
Figure 2. Results from the simulation described on https://github.com/migariane/hetmor. One wants to compare the mortality risk after 1 year of patients with dual therapy (radio- and chemotherapy) with patients on dual therapy (chemotherapy only). Known confounders are age, socioeconomic status, comorbidities, and clinical stage. The absolute bias with respect to the marginal causal odds ratio is reported, based on a sample size of 5000, and 10.000 simulation runs.
Appendix
In order to be able to consistently estimate the MOR, the data must satisfy the following assumptions [8]: i) Cancer treatment is independent of the potential mortality outcomes (Y(0), Y(1)) after conditioning on W. This assumption is often referred to as “conditional exchangeability” and one cannot test it using the observed data. It implies that (within the strata of W) the mortality risk under the potential treatment A=1, i.e. P(Y(1)=1|A=1,W) equals the one under treatment A=0, i.e. P(Y(1)=1|A=0,W). In other words: the risk of death for those treated would have been the same as for those untreated if untreated subjects had received, contrary to the fact, the treatment. This is equivalent to assuming that all confounders have been measured. ii) We also assume that within strata of W every patient had a nonzero probability of receiving either of the two treatment conditions, i.e. 0 <P(A=1|W)<1 (positivity). iii) We assume consistency, which states that we observe the potential outcome corresponding with the observed treatment, i.e. for any individual, Y = AY(1) + (1 – A)Y(0). Also, iv) in defining an individual’s counterfactual outcome as only a function of their own treatment, we assume non-interference, meaning that the counterfactual outcome of one subject was not influenced by the treatment of any other. Thus, if we believe these assumptions to hold and the sample size to be sufficient, we may interpret our estimate of the MOR approximately as the marginal causal riks of one-year mortality for cancer patients treated with monotherapy versus dual therapy.
Thank you
Thank you for reading through this epidemiological material.
If you have updates or changes that you would like to make, please send me a pull request.
Alternatively, if you have any questions, please e-mail us at miguel-angel.luque at lshtm.ac.uk
You can cite this repository as:
Luque-Fernandez MA, Daniel Redondo Sanchez, Michael Schomaker (2018). Effect modification and collapsibility when estimating the effect of interventions: A Monte Carlo Simulation comparing classical multivariable regression adjustment versus the G-Formula based on a cancer epidemiology illustration. GitHub repository, https://github.com/migariane/hetmor.
Twitter @WATZILEI
References
- Spiegelman D, Zhou X. Evaluating Public Health Interventions: 8. Causal Inference for Time-Invariant Interventions. Am J Public Health. 2018:e1-e4.
- Greenland S, Robins JM, Pearl J. Confounding and collapsibility in causal inference. Statistical Science. 1999;14(1):29-46.
- Sjolander A, Dahlqwist E, Zetterqvist J. A Note on the Noncollapsibility of Rate Differences and Rate Ratios. Epidemiology. 2016;27(3):356-359.
- Keil AP, Edwards JK, Richardson DB, Naimi AI, Cole SR. The parametric g-formula for time-to-event data: intuition and a worked example. Epidemiology. 2014;25(6):889-897.
- Greenland S, Robins JM. Identifiability, exchangeability, and epidemiological confounding. International journal of epidemiology. 1986;15(3):413–419
- Snowden JM, Rose S, Mortimer KM. Implementation of G-computation on a simulated data set: demonstration of a causal inference technique. Am J Epidemiol. 2011;173(7):731-738.
- Sofrygin O, van der Laan MJ, Neugebauer R (2015). simcausal: Simulating Longitudinal Data with Causal Inference Applications. R package version 0.5.
- Luque Fernandez MA, Schomaker M, Rachet B, Schnitzer ME. Targeted maximum likelihood estimation for a binary treatment: A tutorial. Stat Med. 2018;37:2530-2546.